Event Based Pipelines - An Introduction
Background
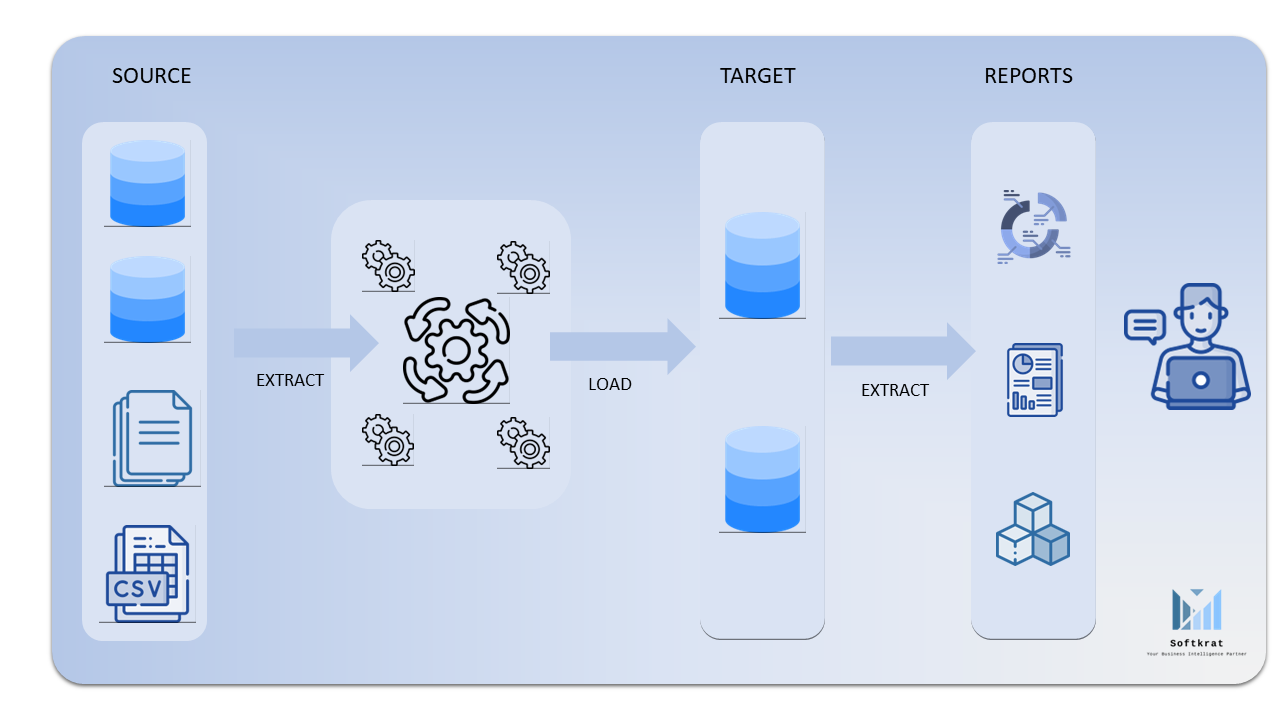
Fig 1. A Traditional ETL Implementation
In the good old days of data warehousing, we would often cringe at the suggestion of processing the ETL pipeline for anything less than a day. For large data warehouses processing some large tables every three days was considered acceptable. The demands of business, however, continued to call for more real-time processing. One of the data warehouses that I managed, was refreshing in every 15 – 30 minutes, was considered slow and outdated!
“I still do not like it”, said one of my users, “why cannot I see the data in the warehouse as soon as it changes in the app”. “Well, “I said, “there are two issues – 1. How do I process it super quickly? 2. How do I know something has changed immediately?”
Advent of Extract, Load & Transform
With the passage of time, increased processing capabilities, and reduced cost of storing data, made the ELT (Extract, Load, and Transform) pipeline more acceptable, unlike the traditional ETL (Extract Transform, and Load) transformations where a huge amount of time is spent in the processing of data.
One benefit of ELT is that it can take advantage of the processing power and scalability of modern target systems, such as data lakes or cloud-based data warehouses, to perform the transformation. This can result in faster processing and more efficient use of resources. However, ELT can also require more storage space in the target system due to the need to store the raw data before the transformation.
With the first issue of processing data quickly resolved, let’s look at the second issue –knowing immediately when something has changed. This brings us to the event-driven pipelines.
Event-driven pipelines are a popular approach to building data processing systems that can handle large volumes of data in real time. They offer a flexible and scalable solution to processing data from a variety of sources, including IoT sensors, web applications, and financial systems. In the next few sections, we will explore the key components of event-driven pipelines, how they work, and some of their benefits and challenges.
What are event driven pipelines
At a high level, an event-driven pipeline is a system that processes events as they occur, rather than waiting for a batch of data to be collected and processed later. This approach allows for near real-time processing of data, which is often critical for applications such as fraud detection or system monitoring, amongst others.
In an event-driven pipeline, data is generated by a variety of sources, such as sensors, applications, or user interactions. This data is then sent to an event processing system, which receives and processes the data as it arrives. The system can then perform a variety of operations on the data, such as filtering, aggregation, or enrichment, before passing it on to downstream systems or applications.
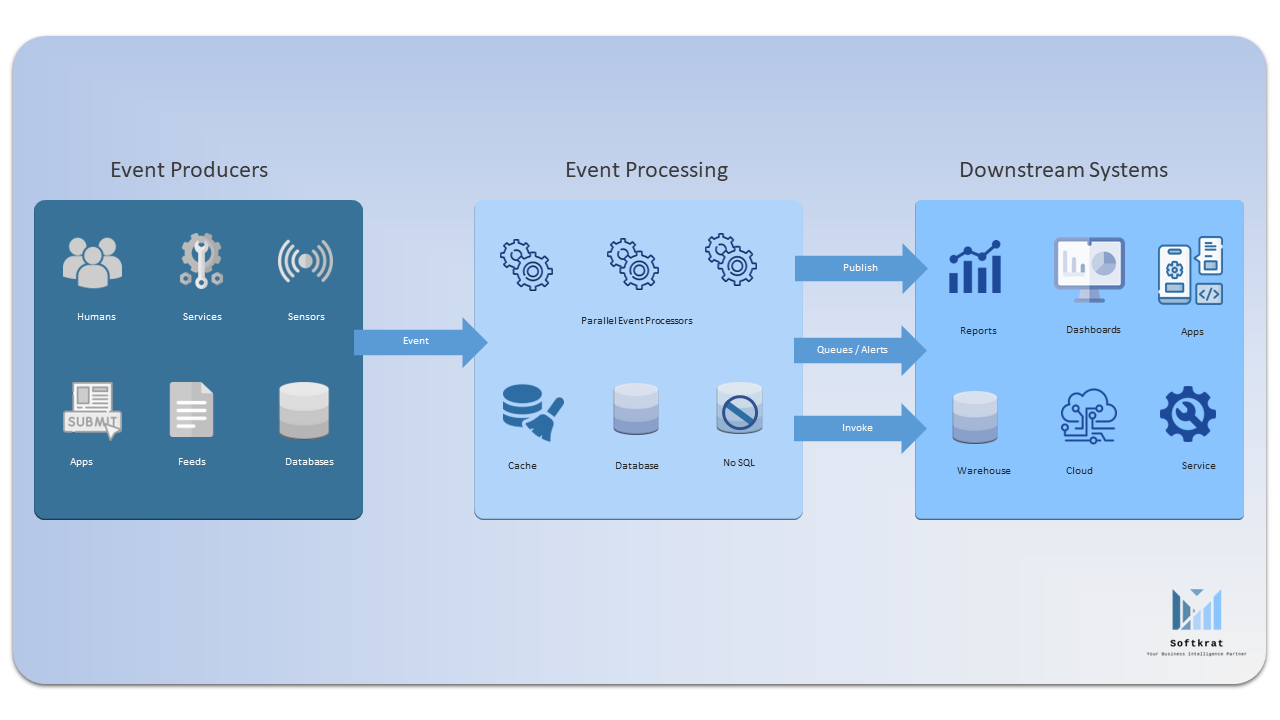
Event-driven pipelines are designed to be highly scalable and fault-tolerant. By processing events in parallel across multiple nodes, event-driven pipelines can scale to handle even the largest data volumes while maintaining low latency and high throughput. Additionally, event-driven pipelines are designed to handle failures at any point in the processing chain.
For example, if a node in the processing chain fails, the system can automatically re-route data to a backup node, ensuring that data processing continues without interruption.
Key components of event-driven pipelines
Event-driven pipelines consist of several key components, that play a critical role in the processing and management of data. These components include:
- Event producers: Event producers generate data and transmit it to the event processing system. Producers may include sensors, web applications, or other sources of data.
- Event processing system: The event processing system is responsible for receiving and processing data as it arrives. This system may be distributed across multiple nodes to handle large volumes of data in real time.
- Event processing algorithms: Event processing algorithms are used to perform several operations on the data, such as filtering, aggregation, or enrichment. These algorithms may be customized for specific use cases, such as fraud detection or system monitoring.
- Storage: The event processing system may store data in a variety of formats, including databases, message queues, or distributed file systems.
- Downstream systems: Once data has been processed, it may be passed on to downstream systems or applications for further analysis or action. Some examples include data visualization tools, machine learning models, or other processing systems.
Benefits of event-driven pipelines
Event-driven pipelines offer several benefits over traditional batch processing systems. These benefits include:
- Real-time processing: Event-driven pipelines are designed to process data in real time, as it arrives. This allows for near real-time processing of data, which is critical for applications such as fraud detection or system monitoring, and others.
- Scalability: Event-driven pipelines are highly scalable and can handle large volumes of data in real time.
- Flexibility: Since events are processed as they arrive, rather than being batched together, the system can adapt to changing data volumes and processing requirements in real-time. This means that event-driven pipelines can easily handle spikes in data volume or changes in data sources, without requiring significant changes to the underlying architecture.
- Fault-tolerance: Event-driven pipelines are designed to handle failures at any point in the processing chain. For example, if a node goes down, the data automatically gets re-routed through the backup node.